Have you ever wondered why sometimes the data you have deleted from the Milvus vector database still appear in the search results?
A very likely reason is that you have not set the appropriate consistency level for your application. Consistency level in a distributed vector database is critical as it determines at which point a particular data write can be read by the system.
Therefore, this article aims to demystify the concept of consistency and delve into the levels of consistency supported by the Milvus vector database.
What Is Consistency?
Before getting started, we need to first clarify the connotation of consistency in this article, as the word "consistency" is an overloaded term in the computing industry. Consistency in a distributed database specifically refers to the property that ensures every node or replica has the same view of data when writing or reading data at a given time. Therefore, here we are talking about consistency as in the CAP theorem.For serving massive online businesses in the modern world, multiple replicas are commonly adopted. For instance, online e-commerce giant Amazon replicates its orders or SKU data across multiple data centers, zones, or even countries to ensure high system availability in the event of a system crash or failure. This poses a challenge to the system - data consistency across multiple replicas. Without consistency, it is very likely that the deleted item in your Amazon cart reappears, causing a very bad user experience.
Hence, we need different data consistency levels for different applications. And luckily, Milvus, a database for AI, offers flexibility in consistency level, and you can set the consistency level that best suits your application.
Consistency in the Milvus Vector Database
The concept of consistency level was first introduced with the release of Milvus 2.0. The 1.0 version of Milvus was not a distributed vector database, so we did not involve tunable levels of consistency then. Milvus 1.0 flushes data every second, meaning that new data are almost immediately visible upon their insertion and Milvus reads the most updated data view at the exact time point when a vector similarity search or query request comes.However, Milvus was refactored in its 2.0 version, and Milvus 2.0 is a distributed vector database based on a pub-sub mechanism. The PACELC theorem points out that a distributed system must trade off between consistency, availability, and latency. Furthermore, different levels of consistency serve different scenarios. Therefore, the concept of consistency was introduced in Milvus 2.0, and it supports tuning levels of consistency.
Four Levels of Consistency in the Milvus Vector Database
Milvus supports four levels of consistency: strong, bounded staleness, session, and eventual. And a Milvus user can specify the consistency level when creating a collection or conducting a vector similarity search or query. This section will continue to explain how these four levels of consistency are different and which scenario they are best suited for.1. Strong
Strong is the highest and the most strict level of consistency. It ensures that users can read the latest version of data.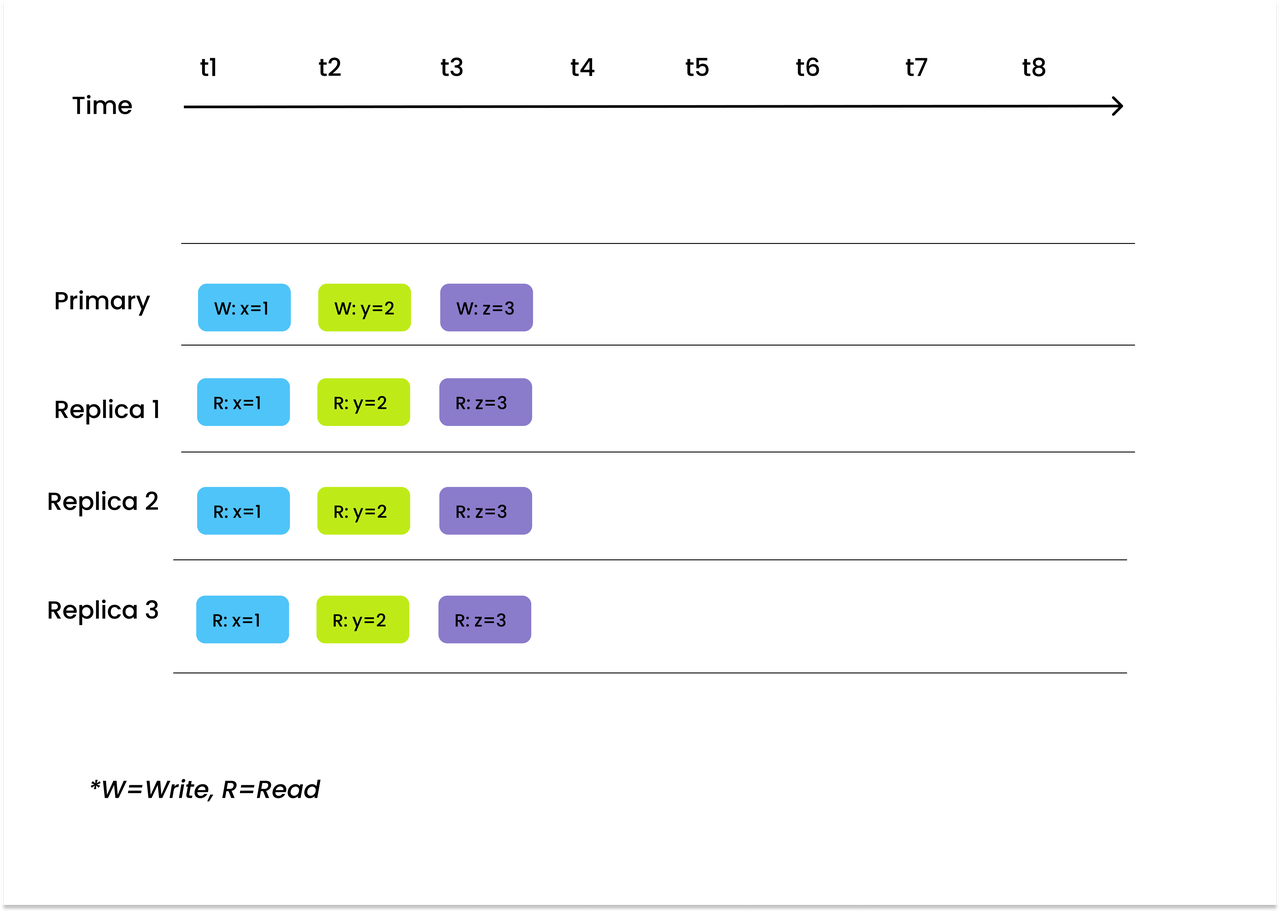
An illustration of strong consistency.
from DZone.com Feed https://ift.tt/p4qfOWa
No comments:
Post a Comment